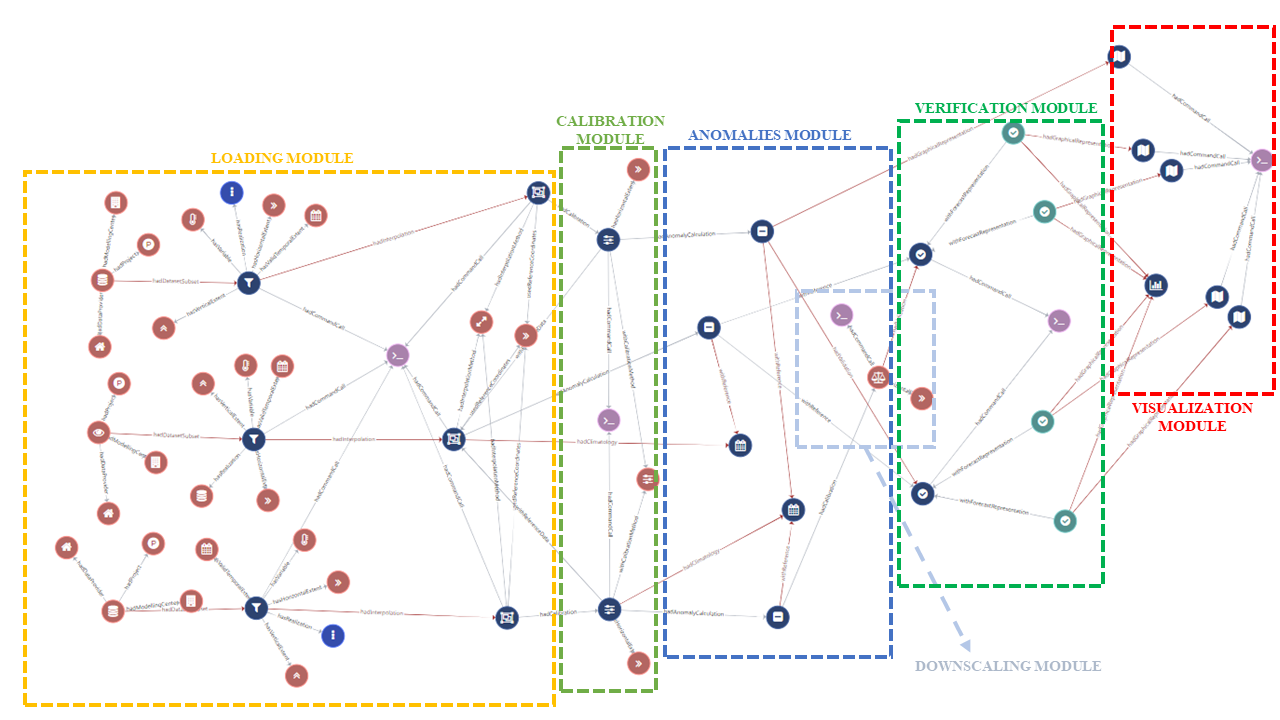
Second draft of how we could address the ontology expansion. Considering that most of the added terms align well with the current ontology, I've proposed extending the already defined ontologies cal: and val:. Additional individuals may be included in the future. Currently, such an extension could enable us to generate nearly complete provenance for SUNSET. It's important to note that this proposed expansion is still preliminary and requires thorough review.
(All definitions need to be reviewed before presenting them to the METACLIP maintainers.)
GITHUB ISSUE: https://github.com/metaclip/vocabularies/issues/5#issuecomment-2037878749
@nperez @vagudets
- TERMINOLOGY NOTES
Each element (either class, individual or object property in this particular case) is defined by means of "Annotation properties". The most used ones are defined as follows:
-
dc:title: "..."
-
dc:comment: "A description of the subject resource."
-
dc:description: "..."
-
seeAlso: "Further information about the subject resource."
-
ReferenceURL: "An active web link providing an authoritative technical description of the resource"
-
hasProbCharacter: "Probabilistic nature of the adjustment approach. Two possible disjoint values: 'stochastic' or 'deterministic'"
-
hasSeasonality: "Describes the procedure followed to deal with the seasonal cycle. Typical values for this property are "none" (in case the seasonal cycle is not taken into account), "n-day moving window", "monthly", "seasonal"."
-
isMultiSite: "A data property of the downscaling method that determines whether the :CalibrationMethod is envisaged to reproduce the spatial structure of the observations in the downscaled model outputs"
-
isMultiVariable: "A data property of the downscaling method that determines whether the :CalibrationMethod is envisaged to reproduce the observed inter-variable coherence in the downscaled model outputs"
-
isTrendPreserving: "A data property of the downscaling method that determines whether the :CalibrationMethod is envisaged to reproduce the observed inter-variable coherence in the downscaled model outputs"
Also, remark the fact that individuals refer to real worlds objects, or events, and types, or classes, to sets of real world objects. Class expressions or definitions gives the properties that the individuals must fulfill to be members of the class. Also, object properties are used to assert relationships between individuals (or instances).
- NEW CLASSES
prov:Entity⇒
cal:CalibrationMethod⇒
cal:ESD⇒
cal:ESD-CSDownscale
*dc:title:"Empirical Statistical Downscaling in R package CSDownscale"
*dc:description:"R package CSDownscale provides a set of statistical downscaling methods for climate predictions, ready to be applied to refine the output of climate predictions"
*seeAlso:https://upcommons.upc.edu/bitstream/handle/2117/384114/9BSCDS_36_CSDownscale%20an%20R%20Package.pdf?sequence=1&isAllowed=y
prov:Entity⇒
prov:Influence⇒
prov:EntityInfluence⇒
prov:Derivation⇒
ds:Step⇒
ds:Transformation⇒
cal:Calibration⇒
cal:Downscaling
*dc:description:“Downscaling refers to the process of refining or disaggregating coarse-scale or large-scale data to a finer spatial or temporal resolution.”
*seeAlso: https://en.wikipedia.org/wiki/Downscaling
prov:Entity⇒
val:VerificationMetrics
*dc:description: "Verification metrics are used to assess the performance and skill of system models by comparing their predictions with observed data"
seeAlso: https://www.cawcr.gov.au/projects/verification/verif_web_page.html
- NEW INDIVIDUALS
- Calibration Methods used in Calibration module
All individuals listed below are instances of cal: ParametricBiasCorrection
cal:CalibrationMethod ⇒
cal:BiasCorrection ⇒
cal: ParamatricBiasCorrection
BiasOnly
dc:description: "This method corrects the bias in the system. It does not address variance discrepancies between the system and observation"
comment: "For more details, see the CSTools documentation for CST_Calibration()"
hasProbCharacter: "deterministic"
hasSeasonality: "monthly"
referenceURL: "https://cran.r-project.org/web/packages/CSTools/CSTools.pdf"
EVMOS
dc:title: "Error Variance Minimization Objective Score"
dc:description:"This method not only corrects the bias but also applies a variance inflation technique to ensure that the corrected system maintains correspondence with the variance of the observation. It aims to adjust both bias and variance."
comment: "For more details, see the CSTools documentation for CST_Calibration()"
hasProbCharacter: "deterministic"
hasSeasonality: "monthly"
referenceURL: "https://cran.r-project.org/web/packages/CSTools/CSTools.pdf"
isDefinedBy: "Van Schaeybroeck and Vannitsem, 2011"
MSE_min
dc:title:"Mean Squared Error (Minimizing)"
dc:description:"This ensemble calibration method aims to correct bias, overall system variance, and ensemble spread. It minimizes a constrained mean-squared error using three parameters. The goal is to adjust the system to match the observed variance and spread."
comment: "For more details, see the CSTools documentation for CST_Calibration()"
hasProbCharacter: "deterministic"
hasSeasonality: "monthly"
referenceURL: "https://cran.r-project.org/web/packages/CSTools/CSTools.pdf"
isDefinedBy: "Doblas-Reyes et al. (2005)"
CRPS
dc:title:"Continuous Ranked Probability Score (Minimizing)"
dc:description:"This ensemble calibration method corrects bias, overall system variance, and ensemble spread. It does so by minimizing the Continuous Ranked Probability Score (CRPS) using four parameters. CRPS is a scoring rule that evaluates the probabilistic systems."
comment: "For more details, see the CSTools documentation for CST_Calibration()"
hasProbCharacter: "deterministic"
hasSeasonality: "monthly"
referenceURL: "https://cran.r-project.org/web/packages/CSTools/CSTools.pdf"
RPC
dc:title: "Rank Probability Score"
dc:description:"This method adjusts the system variance to ensure that the ratio of predictable components (RPC) is equal to one. It aims to balance the system variance in relation to the predictability of the system."
comment: "For more details, see the CSTools documentation for CST_Calibration()"
hasProbCharacter: "deterministic"
hasSeasonality: "monthly"
referenceURL: "https://cran.r-project.org/web/packages/CSTools/CSTools.pdf"
- Downscaling methods used in Downscaling module
All individuals listed below are instances of cal: ESD-CSDownscale
cal:CalibrationMethod ⇒
cal:ESD ⇒
cal: ESD-CSDownscale
Int
dc:title: "Interpolation"
dc:description:"Regrid of a coarse-scale grid into a finescale grid, or interpolate model data into a point location. Different interpolation methods, based on different mathematical approaches, can be applied: conservative, nearest neighbor, bilinear or bicubic. Does not rely on any data for training."
dc:comment: "For more details, see the CSTools documentation for CSDownscale"
referenceURL:"https://earth.bsc.es/gitlab/es/csdownscale"
hasProbCharacter: "deterministic"
hasSeasonality: "monthly"
isMultiSite: true?
isMultiVariable: false?
IntLR
dc:title: "Interpolation with Linear Regression"
dc:description:"Interpolate model data into a fine-scale grid or point location. Later, a linear-regression with the interpolated values is fitted using high-res observations as predictands, and then applied with model data to correct the interpolated values."
dc:comment: "For more details, see the CSTools documentation for CSDownscale"
referenceURL:"https://earth.bsc.es/gitlab/es/csdownscale"
hasProbCharacter: "deterministic"
hasSeasonality: "monthly"
isMultiSite: true?
isMultiVariable: false?
IntBC
dc:title: "Interpolation with Bias Correction"
dc:description:"Interpolate model data into a fine-scale grid or point location. Later, a bias adjustment of the interpolated values is performed. Bias adjustment techniques include simple bias correction, calibration or quantile mapping"
dc:comment: "For more details, see the CSTools documentation for CSDownscale"
referenceURL:"https://earth.bsc.es/gitlab/es/csdownscale"
hasProbCharacter: "deterministic"
hasSeasonality: "monthly"
isMultiSite: true?
isMultiVariable: false?
LogReg
dc:title: "Logistic Regression"
dc:description:"Relate ensemble mean anomalies of the large-scale forecasts directly to probabilities of observing above normal/normal/below normal conditions at the local scale using a sigmoid function. It does not produce an ensemble of forecasts but rather their associated probabilities. It is a statistical method with few parameters to train, and only benefits from local information, but it has shown good performance."
dc:comment: "For more details, see the CSTools documentation for CSDownscale"
referenceURL:"https://earth.bsc.es/gitlab/es/csdownscale"
hasProbCharacter: "deterministic"
hasSeasonality: "monthly"
isMultiSite: true?
isMultiVariable: false?
Analogs
dc:title: "Analogs"
dc:description:"Analog interpolation, or Analog Ensemble (AnEn) interpolation, utilizes historical situations resembling current conditions to estimate values at unsampled locations. It selects a subset of similar historical events (analog situations), assigns weights based on similarity, and computes a weighted average of analog values to interpolate values at the target location, offering an alternative approach to traditional interpolation methods. This method captures spatial variability and provides uncertainty estimates, particularly beneficial in areas with complex terrain or sparse observational data."
dc:comment: "For more details, see the CSTools documentation for CSDownscale"
referenceURL: "https://earth.bsc.es/gitlab/es/csdownscale"
hasProbCharacter: "deterministic"
hasSeasonality: "monthly"
isMultiSite: true?
isMultiVariable: false?
-
Verification metrics used in Skill module
All individuals listed below are instances of ver: VerificationMetrics
prov:Entity⇒
ver: VerificationMetrics
EnsCorr
dc:title: "Ensemble Mean Correlation"
dc:description: "Calculate correlation between forecasts and observations for an ensemble forecast, including an adjustment for finite ensemble sizes."
dc:comment: "if \_specs is added at the end of the metric (e.g. FRPSS_specs), the values will be computed using SpecsVerification."
referenceURL: https://cran.r-project.org/web/packages/SpecsVerification/SpecsVerification.pdf
seeAlso: https://cran.r-project.org/web/packages/s2dv/s2dv.pdf
corr_individual_members
dc:title:"Correlation for each individual member of the ensemble"
dc:description:???
ReferenceURL: https://cran.r-project.org/web/packages/s2dv/s2dv.pdf
RPS
dc:title:"Ranked Probability Score"
dc:description: "The Ranked Probability Score (RPS; Wilks, 2011) is defined as the sum of the squared differences between the cumulative forecast probabilities (computed from the ensemble members) and the observations (defined as 0 did not happen and 100 of multi-categorical probabilistic forecasts. The RPS ranges between 0 (perfect forecast) and n-1 (worst possible forecast), where n is the number of categories. In the case of a forecast divided into two categories (the lowest number of categories that a probabilistic forecast can have), the RPS corresponds to the Brier Score (BS; Wilks, 2011), therefore ranging between 0 and 1. The function first calculates the probabilities for forecasts and observations, then use them to calculate RPS. Or, the probabilities of exp and obs can be provided directly to compute the score. If there is more than one dataset, RPS will be computed for each pair of exp and obs data. The fraction of acceptable NAs can be adjusted."
ReferenceURL: https://cran.r-project.org/web/packages/s2dv/s2dv.pdf
RPSS
dc:title:"Ranked Probability Skill Score"
dc:description: "The Ranked Probability Skill Score (RPSS; Wilks, 2011) is the skill score based on the Ranked Probability Score (RPS; Wilks, 2011). It can be used to assess whether a forecast presents an improvement or worsening with respect to a reference forecast. The RPSS ranges between minus infinite and 1. If the RPSS is positive, it indicates that the forecast has higher skill than the reference forecast, while a negative value means that it has a lower skill. Examples of reference forecasts are the climatological forecast (same probabilities for all categories for all time steps), persistence, a previous model version, and another model. It is computed as RPSS = 1 - RPS_exp / RPS_ref. The statistical significance is obtained based on a Random Walk test at the specified confidence level (DelSole and Tippett, 2016). The function accepts either the ensemble members or the probabilities of each data as inputs. If there is more than one dataset, RPSS will be computed for each pair of exp and obs data. The NA ratio of data will be examined before the calculation. If the ratio is higher than the threshold (assigned by parameter na.rm), NA will be returned directly. NAs are counted by per-pair method, which means that only the time steps that all the datasets have values count as non-NA values. "
ReferenceURL: https://cran.r-project.org/web/packages/s2dv/s2dv.pdf
FRPS
dc:title: "Fair Ranked Probability Score"
dc:description: "Calculate the difference (mean score of the reference forecast) minus (mean score of the forecast). Uncertainty is assessed by the Diebold-Mariano test for equality of predictive accuracy."
dc:comment: "if \_specs is added at the end of the metric (e.g. FRPSS_specs), the values will be computed using SpecsVerification."
referenceURL: https://cran.r-project.org/web/packages/SpecsVerification/SpecsVerification.pdf
seeAlso: https://cran.r-project.org/web/packages/s2dv/s2dv.pdf
FRPSS
dc:title: "Fair Ranked Probability Skill Score"
dc:description: "Calculate the difference (mean skill score of the reference forecast) minus (mean skill score of the forecast). Uncertainty is assessed by the Diebold-Mariano test for equality of predictive accuracy. "
dc:comment: "if \_specs is added at the end of the metric (e.g. FRPSS_specs), the values will be computed using SpecsVerification."
referenceURL: https://cran.r-project.org/web/packages/SpecsVerification/SpecsVerification.pdf
seeAlso: https://cran.r-project.org/web/packages/s2dv/s2dv.pdf
CRPS
dc:title: "Continuous Ranked Probability Score"
dc:description: "The Continuous Ranked Probability Score (CRPS; Wilks, 2011) is the continuous version of the Ranked Probability Score (RPS; Wilks, 2011). It is a skill metric to evaluate the full distribution of probabilistic forecasts. It has a negative orientation (i.e., the higher-quality forecast the smaller CRPS) and it rewards the forecast that has probability concentration around the observed value. In case of a deterministic forecast, the CRPS is reduced to the mean absolute error. It has the same units as the data. The function is based on enscrps_cpp from SpecsVerification. If there is more than one dataset, CRPS will be computed for each pair of exp and obs data. "
seeAlso: https://cran.r-project.org/web/packages/s2dv/s2dv.pdf
CRPSS
dc:title: "Continuous Ranked Probability Skill Score"
dc:description: "The Continuous Ranked Probability Skill Score (CRPSS; Wilks, 2011) is the skill score based on the Continuous Ranked Probability Score (CRPS; Wilks, 2011). It can be used to assess whether a forecast presents an improvement or worsening with respect to a reference forecast. The CRPSS ranges between minus infinite and 1. If the CRPSS is positive, it indicates that the forecast has higher skill than the reference forecast, while a negative value means that it has a lower skill. Examples of reference forecasts are the climatological forecast, persistence, a previous model version, or another model. It is computed as ’CRPSS = 1 - CRPS_exp / CRPS_ref. The statistical significance is obtained based on a Random Walk test at the specified confidence level (DelSole and Tippett, 2016)."
ReferenceURL: https://cran.r-project.org/web/packages/s2dv/s2dv.pdf
BSS10
dc:title: "Brier Skill Score (lower extreme)"
dc:description: "Compute the lower extreme Brier score (BS) and the components of its standard decompostion with the two withinbin components described in Stephenson et al., (2008). It also returns the bias-corrected decomposition of the BS (Ferro and Fricker, 2012). It has the climatology as the reference forecast."
dc:comment: "if \_specs is added at the end of the metric (e.g. FRPSS_specs), the values will be computed using SpecsVerification."
referenceURL: https://cran.r-project.org/web/packages/SpecsVerification/SpecsVerification.pdf
seeAlso: https://cran.r-project.org/web/packages/s2dv/s2dv.pdf
BSS90
dc:title: "Brier Skill Score (upper extreme)"
dc:description: "Compute the upper extreme Brier score (BS) and the components of its standard decompostion with the two withinbin components described in Stephenson et al., (2008). It also returns the bias-corrected decomposition of the BS (Ferro and Fricker, 2012). It has the climatology as the reference forecast."
dc:comment: "if \_specs is added at the end of the metric (e.g. FRPSS_specs), the values will be computed using SpecsVerification."
referenceURL: https://cran.r-project.org/web/packages/SpecsVerification/SpecsVerification.pdf
seeAlso: https://cran.r-project.org/web/packages/s2dv/s2dv.pdf
MeanBias
dc:title: "Mean bias of the ensemble"
dc:description: "The Mean Bias or Mean Error (Wilks, 2011) is defined as the mean difference between the ensemble mean forecast and the observations. It is a deterministic metric. Positive values indicate that the forecasts are on average too high and negative values indicate that the forecasts are on average too low. It also allows to compute the Absolute Mean Bias or bias without temporal mean. If there is more than one dataset, the result will be computed for each pair of exp and obs data"
ReferenceURL: https://cran.r-project.org/web/packages/s2dv/s2dv.pdf
MeanBiasSS
dc:title: "Mean Bias Skill Score"
dc:description: "The Absolute Mean Bias Skill Score is based on the Absolute Mean Error (Wilks, 2011) between the ensemble mean forecast and the observations. It measures the accuracy of the forecast in comparison with a reference forecast to assess whether the forecast presents an improvement or a worsening with respect to that reference. The Mean Bias Skill Score ranges between minus infinite and 1. Positive values indicate that the forecast has higher skill than the reference forecast, while negative values indicate that it has a lower skill. Examples of reference forecasts are the climatological forecast (average of the observations), a previous model version, or another model. It is computed as AbsBiasSS = 1 - AbsBias_exp / AbsBias_ref. The statistical significance is obtained based on a Random Walk test at the confidence level specified (DelSole and Tippett, 2016). If there is more than one dataset, the result will be computed for each pair of exp and obs data."
ReferenceURL: https://cran.r-project.org/web/packages/s2dv/s2dv.pdf
EnsSprErr
dc:title: "Ensemble Spread-to-Error Ratio"
dc:description: ??
ReferenceURL: ??
MSSS
dc:title: "Mean Square Skill Score"
dc:description: "Compute the mean square error skill score (MSSS) between an array of forecast ’exp’ and an array of observation ’obs’. The two arrays should have the same dimensions except along ’dat_dim’ and ’memb_dim’. The MSSSs are computed along ’time_dim’, the dimension which corresponds to the start date dimension. MSSS computes the mean square error skill score of each exp in 1:nexp against each obs in 1:nobs which gives nexp * nobs MSSS for each grid point of the array. The p-value and significance test are optionally provided by an one-sided Fisher test or Random Walk test."
ReferenceURL:https://cran.r-project.org/web/packages/s2dv/s2dv.pdf
MSE
dc:title: "Mean Square Error"
dc:description: "Compute the mean square error for an array of forecasts and an array of observations. The MSEs are computed along time_dim, the dimension which corresponds to the start date dimension. If comp_dim is given, the MSEs are computed only if obs along the comp_dim dimension are complete between limits[1] and limits[2], i.e. there are no NAs between limits[1] and limits[2]. This option can be activated if the user wants to account only for the forecasts for which the corresponding observations are available at all leadtimes. The confidence interval is computed by the chi2 distribution."
ReferenceURL: https://cran.r-project.org/web/packages/s2dv/s2dv.pdf
(...COULD ADD ALL THE DataProviders/ModellingCenters and a Project such as SUNSET...)
- NEW OBJECT PROPERTIES
ds:hadDerivation⇒
ds:hadTransformation⇒
cal:hadCalibration ⇒
cal: hadDownscaling
dc:description: "Object property linking a ds:Step with a cal:Downscaling step.
- cal: withDownscalingMethod
cal:withCalibrationMethod⇒
cal: withDownscalingMethod
dc:description: “Object property linking a cal:Downscaling with the description of the cal:ESD-CSDownscale applied”
- ver: withVerificationMetric
val:withVerificationMetric
dc:description:“Object property linking a ver:Verification step with the description of the ver: VerificationMetric applied”