|
|
|
# Problems counting FLOPs in SandyBridge
|
|
|
|
There are [known issues](https://github.com/RRZE-HPC/likwid/wiki/AccuracySandyBridgeEP) to count floating point instructions in SandyBridge and other Intel architectures where these instructions are overcounted.
|
|
|
|
Several tests have been performed to evaluate this overcount and we learned few lessons.
|
|
|
|
|
|
|
|
We have identified that the overcounting does occur when a floating point vectorial instruction is called for data that is not in a register but on memory. It does occur for:
|
|
|
|
```vaddpd (%r9,%rdx,8), %ymm2, %ymm8```
|
|
|
|
But does not occur when all the elements are already in the registers:
|
|
|
|
```vaddpd %ymm12, %ymm3, %ymm13```
|
|
|
|
|
|
|
|
Then, the overcounting does not occur when the arrays are not aligned because there’s a need to pre-load the data in two chunks and then the operation can not be fused with the floating point instruction.
|
|
|
|
|
|
|
|
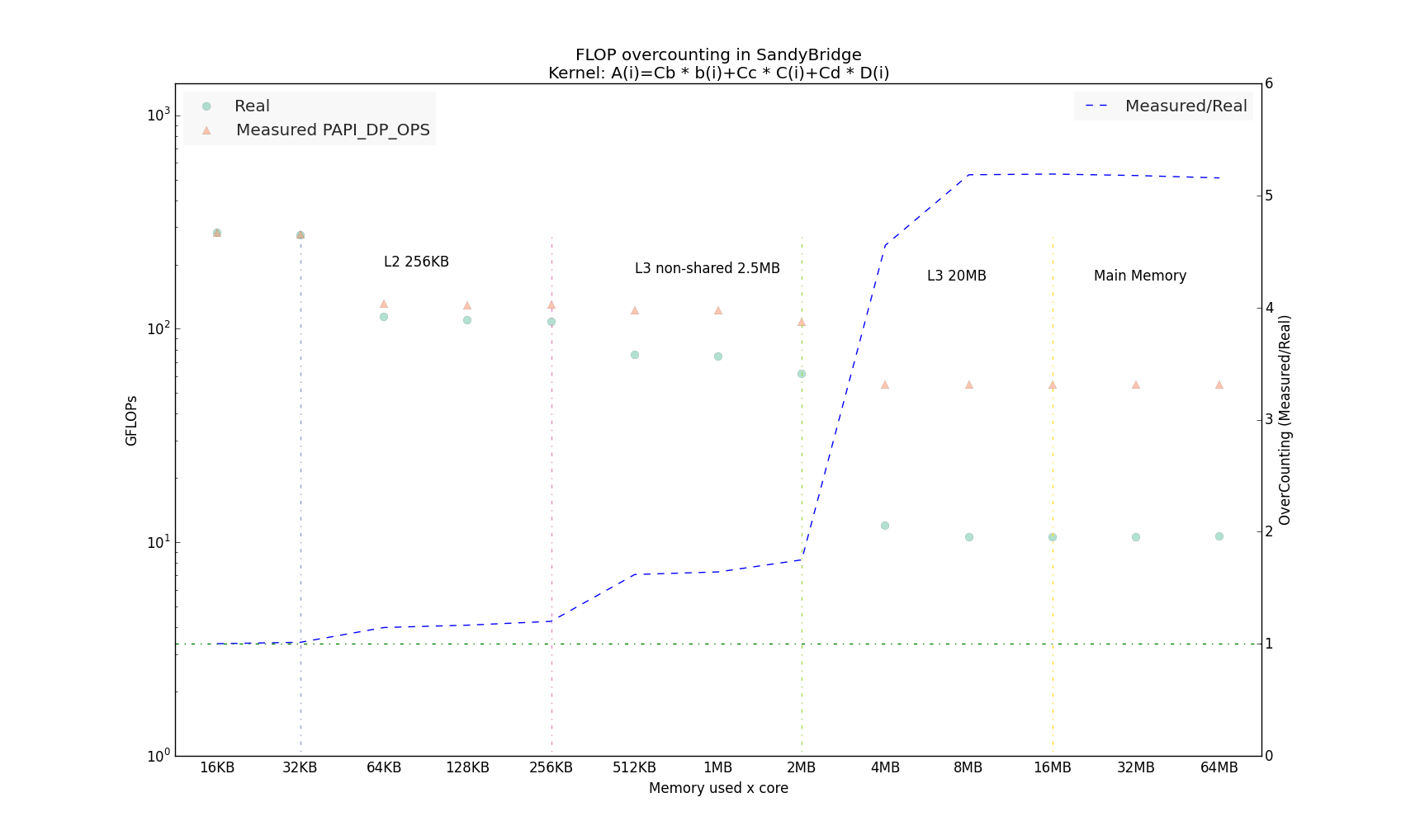
Another finding is that the overcounting is related with the Cache Misses. Whenever the data fits in L1 and in consequence there are no data cache misses the overcounting is almost in-existent, but when the data its placed in lower memory hierarchies the overcounting increases. In the Figure it can be seen that when the objects fit in the L1 cache the instructions reported by the PAPI counters coincide with the ones analytically calculated, reaching in this specific case a overcounting factor of 4 when the objects are stored in the main memory.
|
|
|
|
 |